Dev Debrief #2: An Interview With the Developer of Tube Archivist
Interview with Simon of Tube Archivist - Your self hosted YouTube media server.



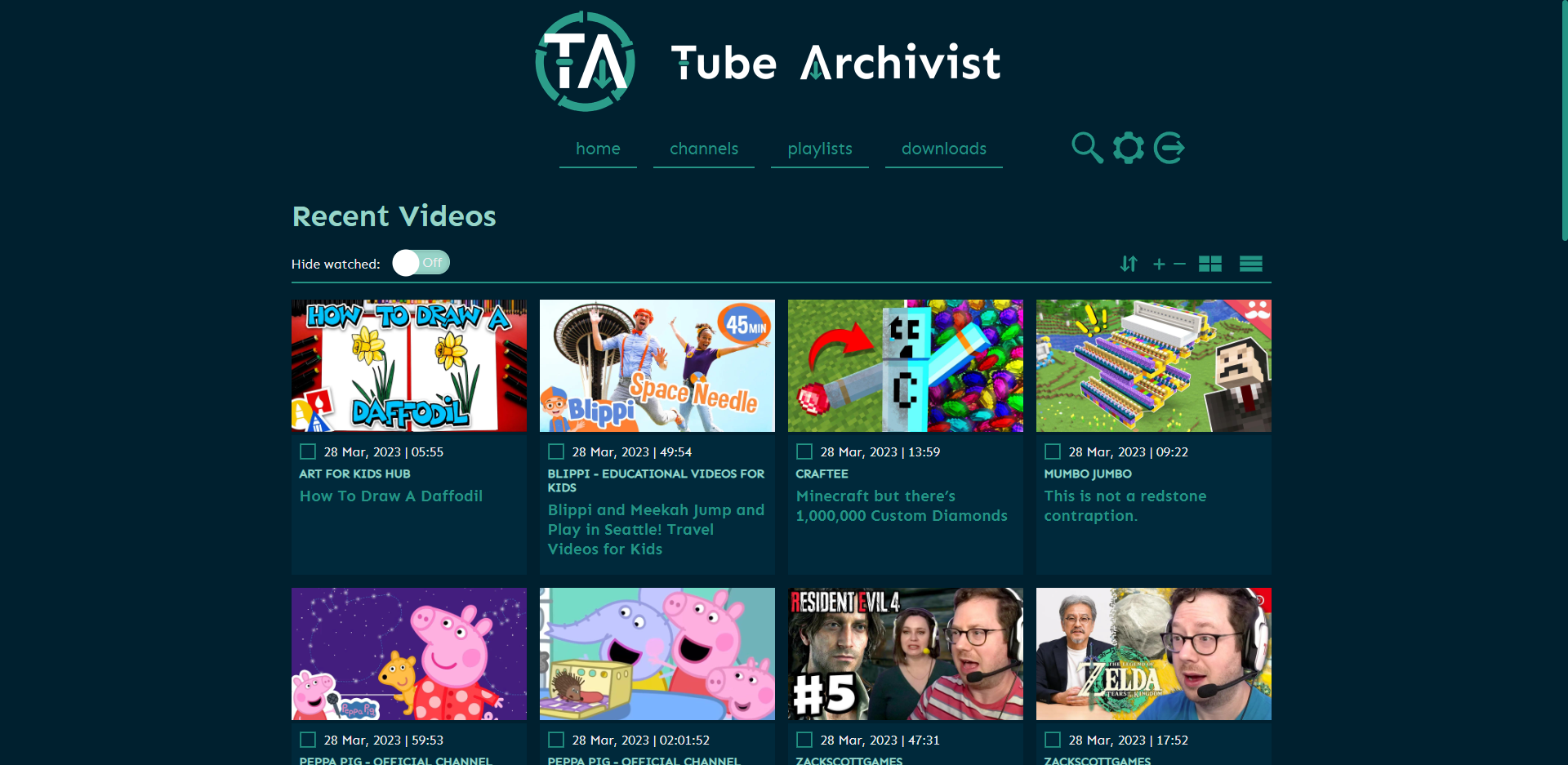
Tube Archivist is a tool that allows users to subscribe to their favorite YouTube channels and download videos using yt-dlp. It indexes and makes the videos searchable, as well as keeps track of viewed and unviewed videos. Users can play the videos directly from the app, making it a useful way to organize and access YouTube content.
- Q: Hey Simon! Can you tell us a little bit about yourself and your background in software development? How did you get started with coding and what inspired you to create Tube Archivist?
It pains me to say this, but it was Windows that inspired me to start programming, but credit where credit is due. That was back in the days when Windows 8 came out, I was deeply annoyed with all the changes, so that’s where I switched to Linux, that alternative OS I read some things about before. And with that change, I realized that I could now make my OS behave how I wanted it to, and not have the OS tell me how I should behave. So I started writing some little Bash scripts to automate some things for me, but quickly ran into limitations, so learning Python was the next logical step. None of that would have happened, probably, without Windows being Windows.
That’s how I got started. I’m what you would call self taught - without wanting to minimize the impact of various amazing teachers on YouTube, blog writers and various people who gave me pointers along the way.
So while learning, following along with YouTube videos, I started downloading them to have them locally available. As my collection grew, this became hard to manage, tutorial playlists were all out of order and I couldn’t find a specific video anymore that I remembered downloading before. So you guessed it, the obvious solution is to write a little Bash script. Piping a find output to rofi for a little menu prompt. That worked quite well for some time, but the limitations became obvious: That was very slow, particularly with the archive on a network share and with an ever growing collection plus I could only search filenames and not additional metadata. So the need for something more complete became obvious, hence Tube Archivist - Your self hosted YouTube media server.

- Q: Can you walk us through the process of how you developed Tube Archivist? What tools and programming languages did you use?
I started by just parsing video metadata and storing that. Initial idea was to make a search API for that metadata to use in my rofi script. But there was this specific global event some time ago that made me underemployed and I had some unexpected time on my hands. So I took the opportunity and wrapped it all up into a more or less complete application. Python made sense, as yt-dlp the underlying software, is also built with Python, so Tube Archivist can directly interact with yt-dlp with native data types.
Then ElasticSearch is doing a lot of the heavy lifting of text searching, indexing and processing. Tube Archivist can be configured to do full text indexing and searching, so you can search as you type over all your subtitles of your videos within milliseconds to find what you are looking for, even over multiple GBs of raw text data.
- Q: What was the most difficult challenge you faced during the development process of Tube Archivist?
It’s not the actual programming that’s the difficult part, it’s managing the project, at least that is my experience. Every time I get stuck with a programming problem, I always find a solution, either on my own or by this time actually really reading the documentation and not just skimming it or from the infinite wisdom of Stack Overflow or from generous experts in the field helping me out.
But I was completely unprepared to become a maintainer of a suddenly moderately popular open source project. All of a sudden I had to come up with a roadmap, deal with questions, pull requests, bug reports and define a scope of the project. These are nice problems to have, I know, but that was and still is the stressful part. I’m not pretending that I’ve figured it all out, but I think I’ve gotten better at it over time.
- Q: Tube Archivist is tailored towards a specific audience. Can you tell us who this audience is, and how your application meets their needs?
It’s built to scale as is, 100k videos and up. I know of people in our Discord with 500k to 1M of videos archived and indexed, all with full text search and archived comments. The application will work nicely for any archive size, but you’ll have some unnecessary overhead if you just want to download a handful of videos here and there.
Plus additional to the downloader, it tries to be its own media server. I’ve looked into the various options out there to index YouTube videos into existing media server solutions. These are all great projects and might be a perfectly good solution for folks out there, but I was not happy with the compromise these projects have to make in how the metadata is stored, indexed and searched. With a dedicated YouTube solution, there is a lot more flexibility to build the application around the metadata and not the other way around.
- Q: What steps do you take to ensure the Tube Archivist is compatible with a wide variety of hardware and software configurations? Has Docker made it easier or more difficult to support the project?
You’d think so, no? The promise of Docker, the abstraction that should take care of all the hardware, filesystem, processor architecture variations out there. But that’s quite far from reality. There are huge differences between the filesystems, some are compatible, others are not, it’s a mess. I try to accommodate when issues come in, but some options are just incompatible.
I was under the impression that we - the self hosting community - kind of agreed on Docker Compose as the package manager for Docker, as an easy and reproducible way to install, configure and start multiple containers with a single command from a single text file. In my opinion it doesn’t get much more convenient than that. But I quickly realized that I was very wrong with this assumption, there are a good amount of platforms out there who make their own additional abstraction around Docker. They look easy and compatible at first glance, but these are the difficult ones to support. Mainly because I never had a use for that, plus they all make their own little changes and variations, that makes it hard to debug. But that’s also where I rely on the community for help.

- Q: Open-source software often relies heavily on community contributions and feedback. How has user feedback influenced the development of Tube Archivist, and how do you encourage and incorporate user feedback into your work?
This project has benefited massively from people providing bug reports. Everytime I think we covered all the edge cases, somebody comes along and proves me wrong. There have also been various great ideas to improve the project, some I could already incorporate, others are on the roadmap, I will eventually get to it. I’m also very happy to have a great group of people helping out on Discord and in the GitHub issues, that takes a lot of pressure away from me.
- Q: Can you shed some light on the community's involvement in contributing to the open source codebase?
I had a good amount of contributors help with extending the front end part of the application, that is not my area of expertise. JavaScript has this very annoying habit of not doing what I tell it to do, not sure why that is, so I’m very grateful for all the help there. Also with Tube Archivist Companion, the browser extension, that recently crossed the hard to fathom threshold of 1000 active users, I had help from amazing people implementing the more tricky parts.
Unfortunately when it comes to Python backend development, I’ve been mostly on my own.
- Q: How do you see Tube Archivist evolving in the future? Can you give us any hints at what new features may be released in future updates?
Tube Archivist relies on constant polling to find new videos from your subscribed channels. That is not ideal, if you have a lot of channels you want to monitor, maybe they upload once per week or once per month or even less frequently, but you might be polling once or twice per day, or even something crazy like once per hour. Wouldn’t it be nice if you could receive notifications from YouTube directly instead when your favorite channels upload? That’s what I’ve been working on with members.tubearchivist.com. This is accessible as a sponsor perk that transforms your Tube Archivist into a real time archival project, adding new videos directly to your download queue within minutes after they get published without the need for constant polling.
On the main project, I have put a break on working on new features for the time being. Past few months and probably the next few months, I’ve been focusing on improving the code quality and revisiting some early flawed or uninformed decisions. Working on new features is exciting and I’m always happy when I can share some amazing progress, but with that switch, this gives me time to work on the backlog, improving the stability, extensibility and overall maintainability of the project. That doesn’t necessarily result in new features, but more in general improved existing features.
- Q: Can you tell the readers what your favorite self-hosted applications are? (other than your own of course)
I have been using Nextcloud for a very long time, I think that was the first project I installed when starting out with my self hosting journey on my little NUC with an old laptop HDD attached. Also Bitwarden/Vaultwarden is one of my all time favorites that I couldn’t live without. I’m also a very excessive Emby user, I wrote various little integrations for that.
How can we follow you?
I'm not super social but you can follow me on Github and we also have a community Discord. We also have a Subreddit r/TubeArchivist.
How you can sponsor Simon and Tube Archivist
Thank you for sharing your story with us!
It's truly fascinating to learn how Windows had sparked your interest in programming and subsequently led to the inception of Tube Archivist. Your unwavering determination to mold your OS into a more personalized platform is highly admirable, and it's evident that your love for programming has driven the creation of a highly commendable YouTube media management tool. Your commitment to enhancing user experience with the deployment of Tube Archivist is both impressive and highly valued by many. We express our gratitude to you for sharing your inspirational journey with us and for your invaluable contribution to the ever evolving realm of open-sourcing and self-hosting!



