Whisper WebUI - The Self-Hosted AI Transcriber
Transcribe audio to text locally using Whisper


We've been testing AI tools for self-hosting, and Whisper WebUI is one that's caught our attention. In this article, we'll take a closer look at its features, capabilities, and how it can be used to streamline your workflow.
What is Whisper WebUI?
Whisper WebUI is way more than just a subtitle generator, it's a full-fledged content translation tool! With Whisper, you can not only generate subtitles, but also do some really cool stuff like translating audio files, transcribing YouTube videos, and even using your own voice to convert spoken words into text.
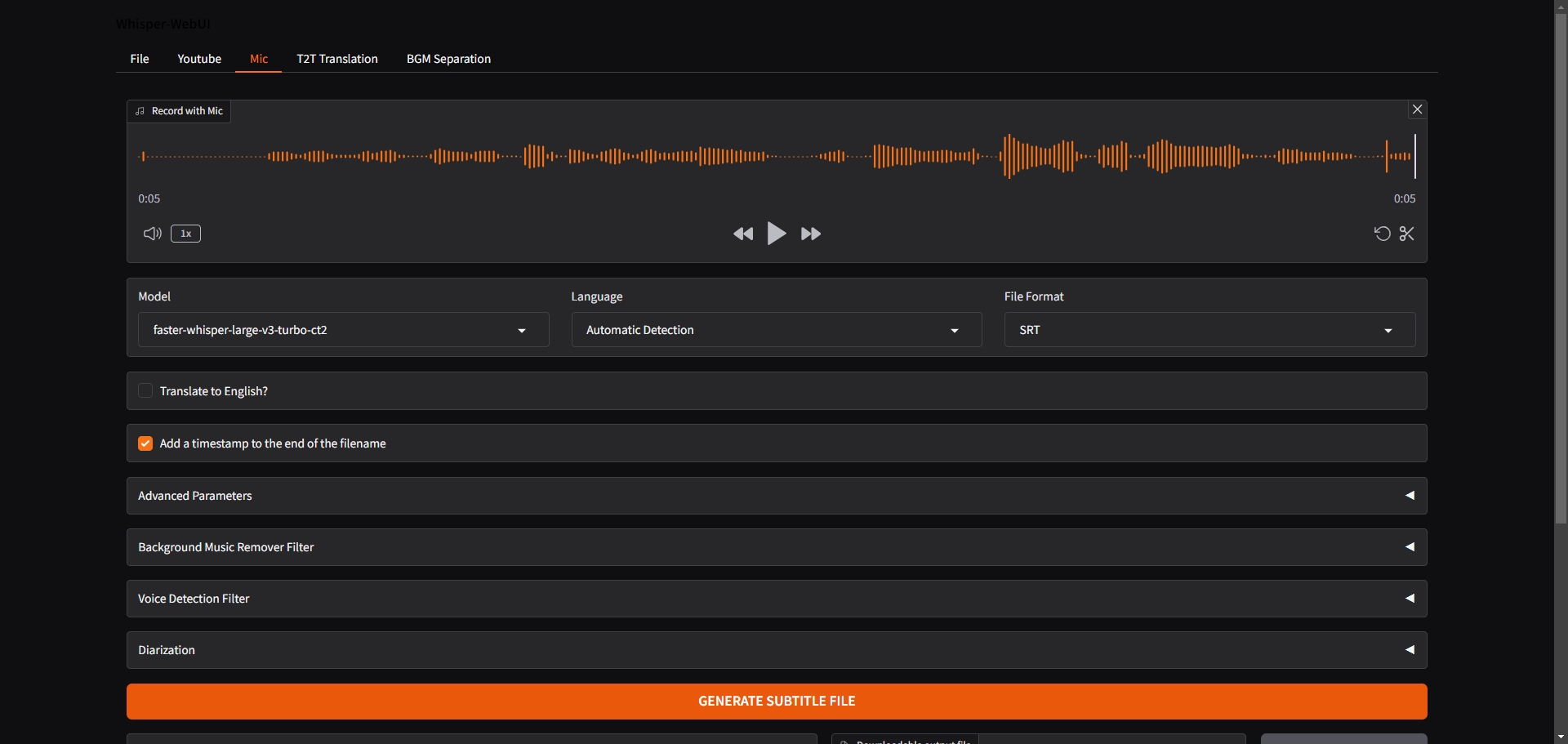
Core Features of Whisper Web UI
- Generate subtitles from various sources: files, YouTube, microphone
- Supports multiple subtitle formats: SRT, WebVTT, txt
- Speech-to-text translation and text-to-text translation capabilities
- Pre-processing and post-processing tools for audio input and output
What is Whisper?
Whisper is a multimodal speech recognition model that has been trained on a large and diverse dataset of audio materials. Its architecture enables it to perform multiple linguistic tasks in parallel, including multilingual speech recognition, translation, and language identification.
What is WebVTT?
WebVTT is a format that provides a way to display timed text, such as subtitles or captions, on top of video content. It allows you to define and manipulate these text tracks, which can include information like chapter titles, audio descriptions, and other metadata. The WebVTT API makes it easy to work with this format, enabling features like automatic captioning, easier navigation, and more.
What is SRT?
SRT stands for SubRip Subtitle file format. It's a widely used format for storing subtitles or captions that are time-aligned with audio or video content.
Install Whisper WebUI using Docker
To install Whisper WebUI on your server, use this Docker Compose stack, which makes the process easy to follow. If you're new to self-hosting, don't worry, we have guides available to help you get started with self-hosting. For information on the latest features and updates, refer to the Whisper WebUI Github.
services:
app:
# build: .
image: jhj0517/whisper-webui:latest
volumes:
# Update paths to mount models and output paths to your custom paths like this, e.g:
# - C:/whisper-models/custom-path:/Whisper-WebUI/models
# - C:/whisper-webui-outputs/custom-path:/Whisper-WebUI/outputs
- /Whisper-WebUI:/Whisper-WebUI/models
- /Whisper-WebUI:/Whisper-WebUI/outputs
ports:
- "7860:7860"
stdin_open: true
tty: true
entrypoint: ["python", "app.py", "--server_port", "7860", "--server_name", "0.0.0.0",]
# If you're not using nvidia GPU, Update device to match yours.
# See more info at : https://docs.docker.com/compose/compose-file/deploy/#driver
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [ gpu ]This particular stack will utilize your NVIDIA GPU. If you do not have a GPU, please modify the stack above to use your CPU. I have an NVIDIA 2080ti.
The first time you run Whisper WebUI it will take a while to download the Whisper model used for transcription. Using the default settings below, it will download the Whisper large-v2 model so it may take a couple minutes to download the 2.8GB file.
Running this on my NVIDIA 2080ti with 11GB of VRAM, the complete VRAM used was ~4GB on the larg-v2 model. It took 23 seconds to complete a transcription on a 6 minute YouTube video. Not bad!

No additional configuration is required, however, some users may find value in adjusting some of the settings to further customize their subtitle generation process.
When using Whisper WebUI with its tiny model, I obtained very similar results to those achieved with the larger model, despite the much shorter processing time. There was no noticeable improvement in the transcript's accuracy or quality, which was an interesting observation. Perhaps with longer videos it may be more noticeable.
Adding Models from Hugging Face
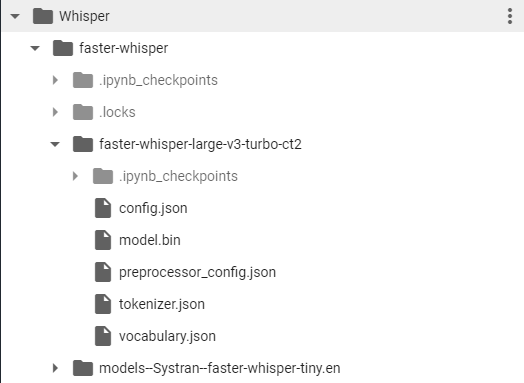
If you want to add more models to use from Hugging Face, you can do so by following this folder format.
The model should work fine if you place the model files (including metadata files) in the Whisper-WebUI\models\Whisper\faster-whisper.
This is an example directory structure for the faster-whisper-large-v3-turbo-ct2 :
Final Notes and Thoughts
Before using Whisper WebUI with your microphone, ensure you're using a secure connection in your browser. A standard local connection may not work, so consider using a reverse proxy or Cloudflare tunnel instead. While this will enable audio input, please be aware that Whisper WebUI does not have built-in authentication measures, which means exposing it to the public could pose security risks.
Swing by the Whisper WebUI GitHub repo and give it a star. If you have questions or would like to suggest new features, visit the issue tracker to get involved. Your feedback is important in helping to improve the project!



